Write Behind with Coherence Federated Caching
Having your Coherence cluster running in the Federated Caching mode it could be tricky to introduce a baking-map schema for cached data persistence. Oracle documentation has the following disclaimer for the Write-Behind Caching feature:
For use with Partitioned (Distributed) and Near cache topologies. Replicated and Optimistic caches should not be used.
Does it mean that we have no chance to use this nice feature if have the Coherence cluster running in the Federated Caching mode? Let’s see what can we do here.
Write-Behind Overview
If you want to have your cached data backed up to some persistent storage, Coherence data grid could do it for you automatically with Write-Behind Caching feature.
It will allow you to read your data from DB through the cache, get it cached for defined time (see expiry-delay configuration guide), being modified if needed and, finally, persist all introduced updates back to DB at a configured interval.
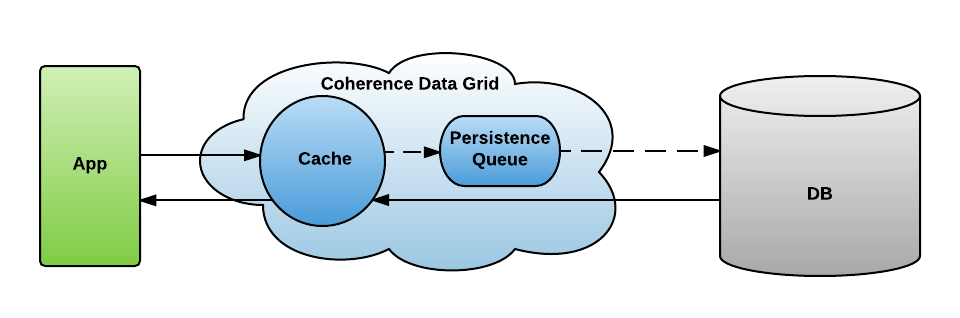
Because of all your updates are postponed and then persisted to DB asynchronously, this backing up process won’t affect your application’s performance anyhow. Please note, that it’s valid only for inserts and updates, remove operation is synchronous here.
Limitations with Write-Behind in Distributed Caching
If you have your application running in several data centers, most likely your databases are running in a sync mode replicating all the data across all clusters (e.g. with help of Oracle GoldenGate). Saying that, it’s not recommended to enable Write-Behind feature for Federated (Replicated) cache:
For use with Partitioned (Distributed) and Near cache topologies: Read-through/write-through caching (and variants) are intended for use only with the Partitioned (Distributed) cache topology (and by extension, Near cache). Local caches support a subset of this functionality. Replicated and Optimistic caches should not be used.
Having enabled Write-Behind feature for all your Coherence clusters will put you in a trouble during your new record’s delayed persistence:
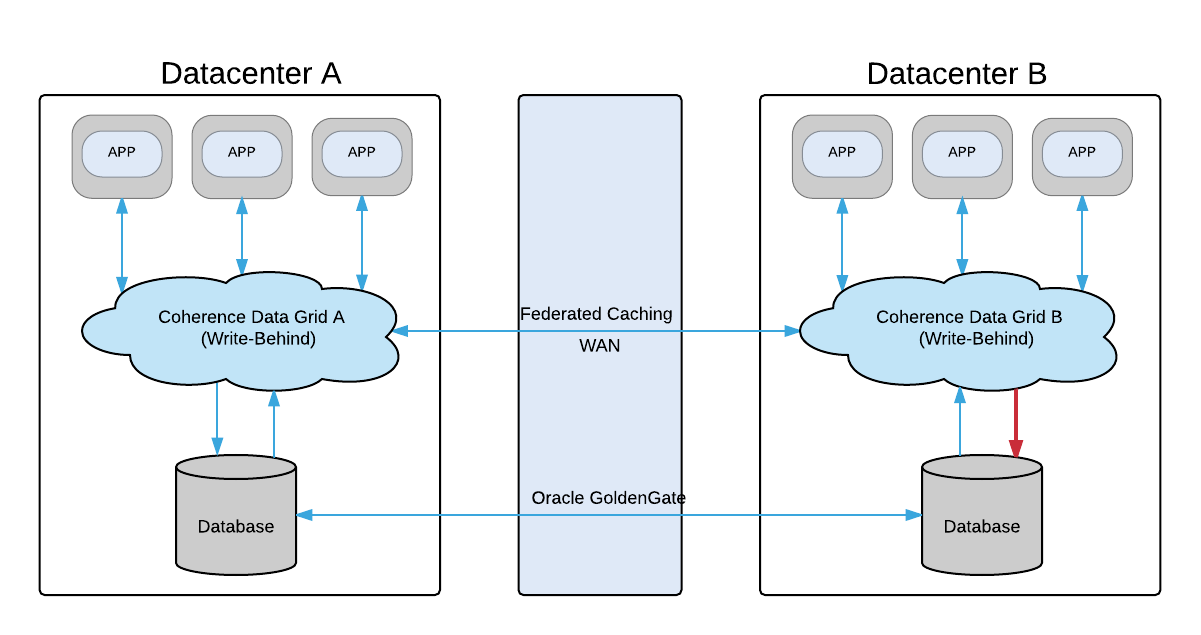
All Coherence data grids will be trying to persist the same data independently, so only the very first insert will be successful, all the others obviously will end up with constraint violation exception.
Write-Behind with Read-Through in Federated Caching
As a possible workaround you might want to have only one Coherence cluster with enabled Write-Behind. All the others should be running in Read-Through mode:
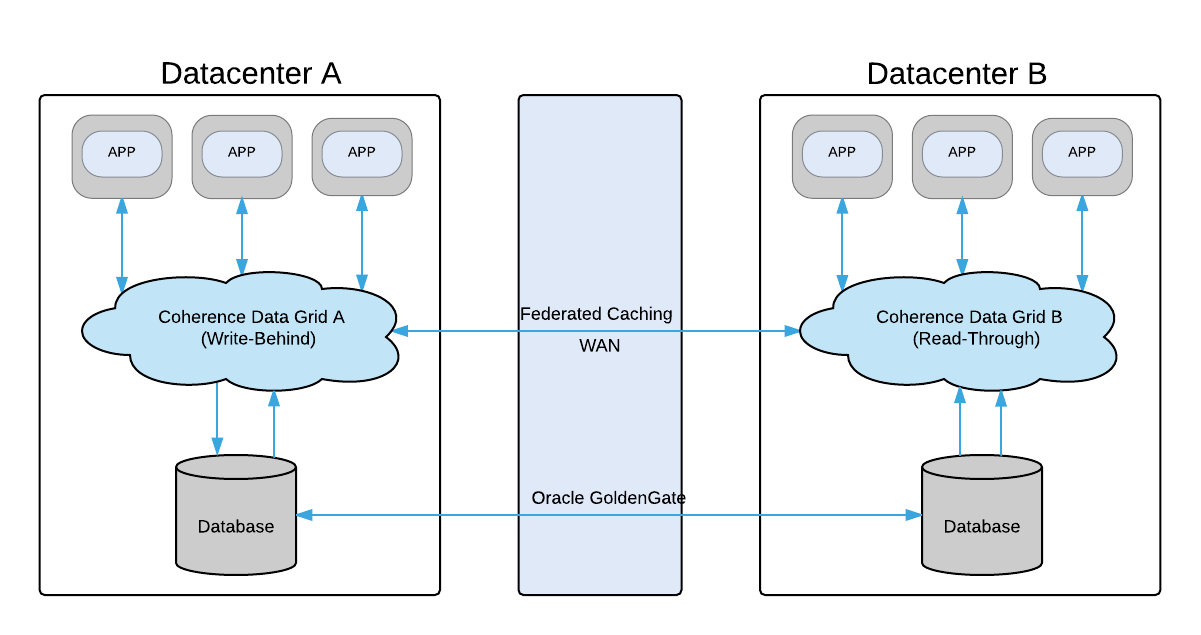
Such architecture will allow your data be replicated across all your data centers and continuously backing up by Coherence to your favourite data storage.
Also, consider to have both configuration settings available on your Coherence servers:
coherence-config-write-behind.xmlcoherence-config-read-through.xml
So, if needed you can easily get your Coherence server switched from Read-Through to Write-Behind mode adding -Dtangosol.coherence.cacheconfig=coherence-config-write-behind.xml JVM parameter to your startup script and restarting the node.